
皆様初めまして。
8月に入社しましたビジネス・ソリューション部の北見です。
私はインフラエンジニアとして5年、その他プログラムを書いたり上流設計を経て
グローディアへやってきました。
そんな私の社内での最初のタスクは
「社内ESXサーバが重いのを何とかする」です。
はい、早速今まで培ってきましたスキルの見せ所です。
ひとまず改善しなければならない事は下記の通りです。
現在の構成
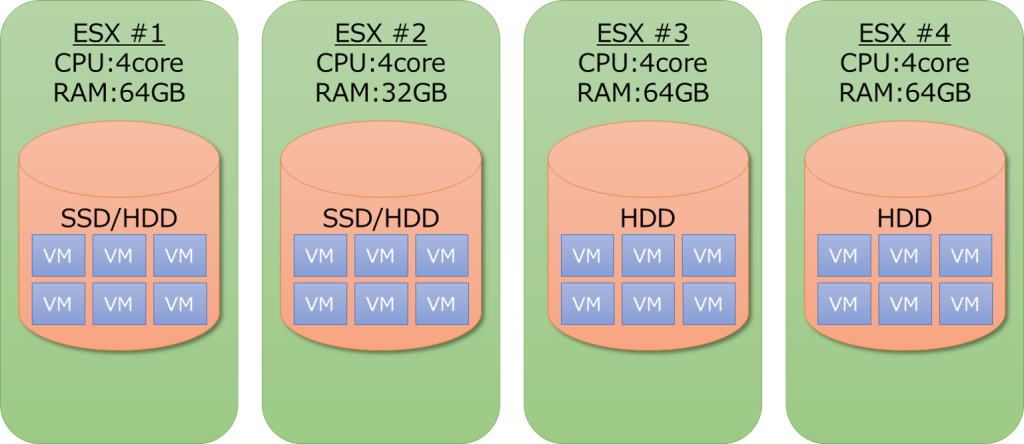
課題
①VMの動作が重いのを何とかしたい
②VMのディスクに耐障害性を持たせたい
③複数のESX間でVMの移動を行いたい
②③の解決方法はすぐに答えが出せますので後者で説明するとして、
①についてはリソース状態を見ないと何とも言えませんので、
まずは現状の調査から行います。
vSphereClient経由で仮想マシン一覧を取得する
仮想マシンが大量に稼働している環境になると、どれだけリソースを利用しているのかを画面上から1台ずつ確認していたら日が暮れてしまいますので、vSphereClientのエクスポート機能を使って表形式で出力を行います。
①まずはvSphereClientでESXiにログインします。
※今回は各ESX毎に作業を行いましたが、vCenterがある環境なら同様の手順でまとめてエクスポートできます。

②vSphereClientの画面から「仮想マシン」タブをクリック。
③仮想マシンの一覧を表示した状態でメニューバーの「ファイル」をクリック。
※適宣仮想マシンのソートや、エクスポートしたい項目をこの画面で行っておくこと。

④「ファイル」-「エクスポート」と開き、「リストのエクスポート」をクリック。
⑤エクスポートファイルの出力先を選択する。
上記の手順でエクスポートすると、下記のような感じで表示されますので、値をエクセルなどにコピーすれば簡単にCPUコア数やメモリの割り当て量などの計算を行うことができます。
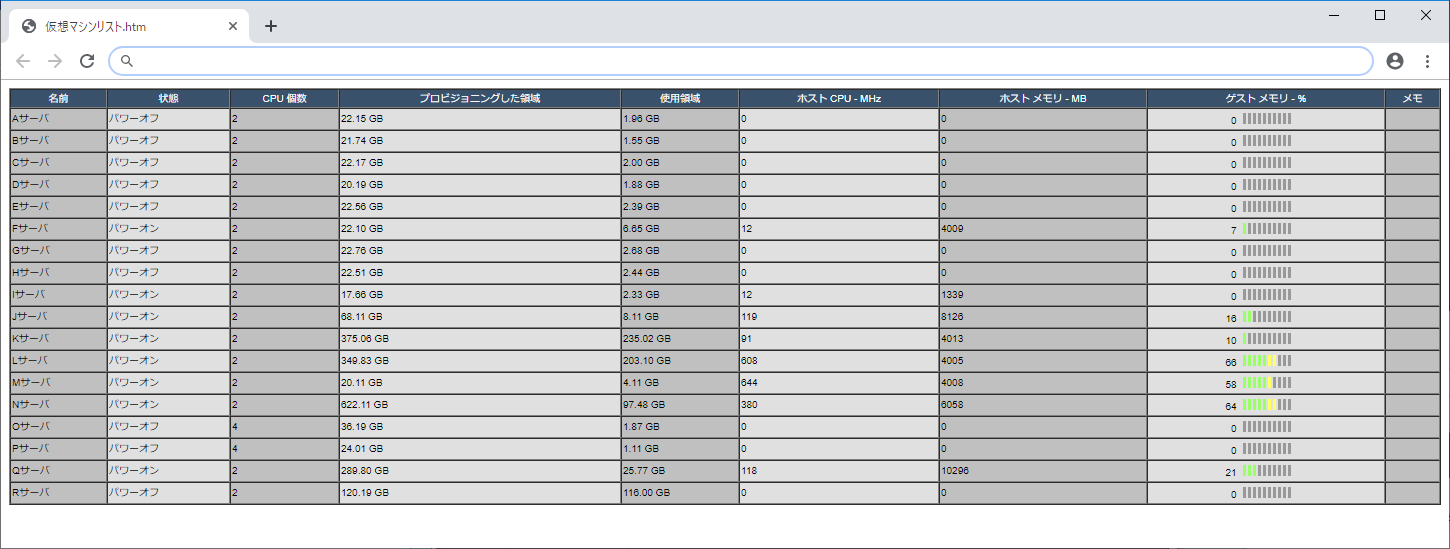
確認結果
さて、上記の取得結果を基にCPUのオーバーコミット率(※1)を確認してみたのですが…
※1:オーバーコミット率・・・物理的なCPU・メモリなどに対して、仮想的に割り当てている割合
(例)物理CPU8コアに対してVMに合計16コア割り当てていたらコミット率200%といった感じ
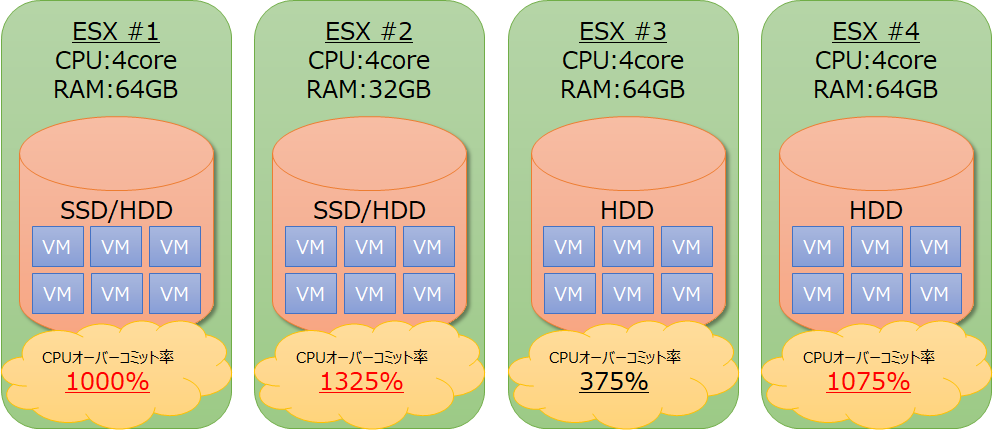
4台中3台が脅威の1000%超えを達成していました!
う~ん、どのVMもアイドル状態とかであればそこまで問題ではないのですが、1台のVMが高負荷とかになると途端に他のVMが引きづられてしまいます。
さらにVMの数が減らせないとなると、流石にホストの増設以外に選択肢がなくなってきます。。。
また、課題の②③にも関連していますが、これだけのVMがローカルの非冗長ストレージに格納されているとなると、ホスト・ディスク障害時の影響が甚大です。
※実際に私が入社するちょっと前にディスクが逝ってしまい、今回の話が浮上した様です…
改善方法
ということで今回の課題の対応策ですが、現在の構成を下記の様にします。
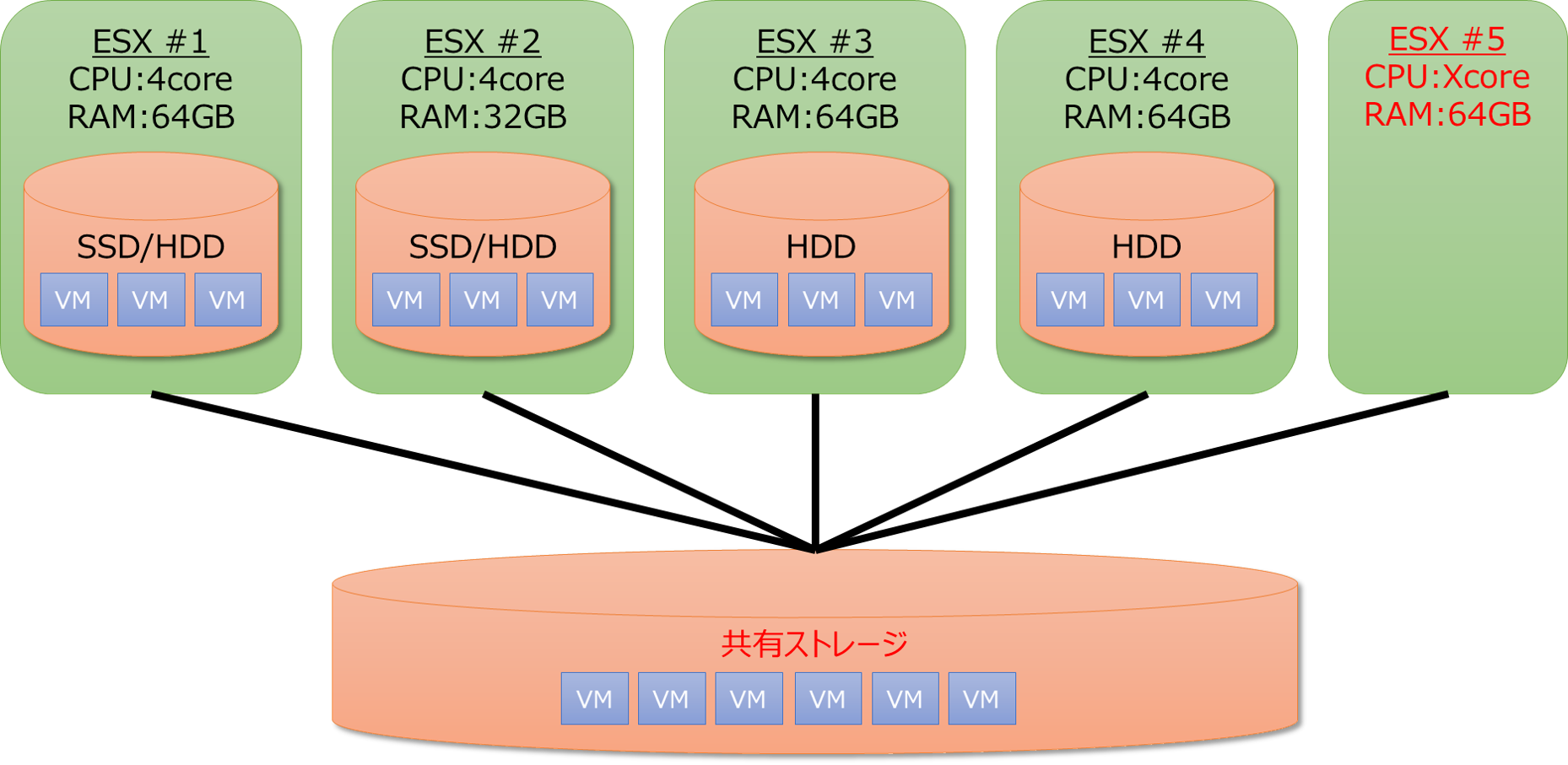
解決策
①VMの動作が重いのを何とかしたい
→新規ホストの増設
…安直な解決策になってしまいましたが、どう考えてもCPUコアの絶対数が足りていませんのでホストを増やす方針で進めます。
②VMのディスクに耐障害性を持たせたい
③複数のESX間でVMの移動を行いたい
→共有ストレージを導入
②を実現させるだけであれば各ホスト上でRAIDを組めば良いのですが、ESXでRAID構成にするにはハードウェアRAIDが必要なのと、③の解決にはならない為、全ESX共有の外部ストレージを導入する事にしました。
改善方針が決まりましたのでお次は機器の選定になりますが、こちらは次回以降に続きます。。