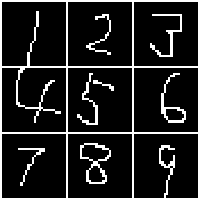
今回は、DeepLearningフレームワークのChainerを試してみます。
手書き数字を識別してみよう、ということでMNISTというデータを使います。
MNISTとは手書き数字画像とそれが何の数字かのラベルがたくさん入っているデータです。
それをDeepLearningすることで手書き数字を識別できるようになります。
また、Chainerに初めて触ったので学習の部分はサンプルコードにやってもらいます。
1.Chainerの準備
まずはChainerを使えるようにしましょう。
pipでChainerを入れます
$ pip install chainer
Chainerのサンプルコードをダウンロードします。
$ git clone https://github.com/chainer/chainer.git
(zipファイルでダウンロードしてもいいです。 https://github.com/chainer/chainer)
2.サンプルコードを実行
ダウンロードしたファイルの中にサンプルコードがあるのでとりあえず実行してみましょう
$ cd chainer/examples/mnist
$ python train_mnist.py
|
1 2 3 4 5 6 7 8 9 10 11 |
GPU: -1 # unit: 1000 # Minibatch-size: 100 # epoch: 20 epoch main/loss validation/main/loss main/accuracy validation/main/accuracy elapsed_time total [#.................................................] 2.50% this epoch [#########################.........................] 50.00% 300 iter, 0 epoch / 20 epochs 30.072 iters/sec. Estimated time to finish: 0:06:29.062148. |
こんな画面が出ます、上のインジケータが100%になれば終了です。
sshなどで端末だけを操作している時にno DISPLAYエラーが出る場合があります。
その場合matplotlibrcファイルを一部書き換える必要があります。
以下のコマンドでpythonインタプリタからファイルの位置を確認して、
|
1 2 3 4 |
$ python >>> import matplotlib >>> matplotlib.matplotlib_fname() |
以下のように書き換えましょう。
- backend : TkAgg
+ backend : Agg
これで問題がなければ動くはずです。
必要モジュールが足りないときは適宜インストールしてください。
終了後にresultフォルダにグラフ画像などができています。
3.サンプルコードの学習モデルで画像識別をする
ただ学習しただけだと、数値とグラフが出ているだけでDeepLearningできた気がしない!
というわけで手書き文字を読み込んで識別するプログラムを作ってみます。
まず、サンプルコードの後ろの方に学習モデルを保存するコードを追加します。
|
1 2 3 4 5 6 7 8 |
# Run the training trainer.run() # 学習モデルを保存するコードを追加 chainer.serializers.save_npz('train_mnist.model', model) if __name__ == '__main__': main() |
追記後にもう一度サンプルコードを実行すると、同フォルダにtrain_mnist.modelができていると思います。
これが先程学習したモデルになります。
モデルと画像を読み込んで、識別結果を出すプログラムが以下になります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
import chainer, numpy import chainer.functions as F import chainer.links as L from PIL import Image class MLP(chainer.Chain): def __init__(self, n_units, n_out): super(MLP, self).__init__() with self.init_scope(): # the size of the inputs to each layer will be inferred self.l1 = L.Linear(None, n_units) # n_in -> n_units self.l2 = L.Linear(None, n_units) # n_units -> n_units self.l3 = L.Linear(None, n_out) # n_units -> n_out def __call__(self, x): h1 = F.relu(self.l1(x)) h2 = F.relu(self.l2(h1)) return self.l3(h2) model = L.Classifier(MLP(1000, 10)) chainer.serializers.load_npz('train_mnist.model', model) image = Image.open("3.png").convert('L') image = numpy.asarray(image).astype(numpy.float32) / 255 image = image.reshape((1, -1)) result = model.predictor(chainer.Variable(image)) print numpy.argmax(result.data) |
モデルのクラスは保存したときと同じ必要があるらしいため、サンプルコードからの流用です。
また、読み込む画像サイズは28×28の必要があります。
![]()
ペイントで書いたこの画像を読み込んだところ、3と正しく結果が出力されました!
他にもいろいろ試し、正答率はまあまあ高かったですが7がうまく識別できませんでした。
今回は画像の識別でしたが、他のDeepLearningにも触れてみたいものですね。